Tutorial: Typing in the air using Chrome, depth camera and WebGL transform feedback
aleksandar.stojiljkovic@intel.com
Note: this tutorial is work in progress and the final version is expected to be published on 01.org in following days.
When I showed this first to my friend Babu, he said something on the line of “that’s not convenient”. Well, though I can type on it faster than scrolling through the character grid, it is correct - it is not convenient, but it is a good illustration for a tutorial.
Few words about the setup first. Plug the Intel® RealSense™
SR300 to USB 3.0 port of your Linux/Windows or Chrome OS machine. As a near-range camera, SR300 fits well for the use case here. The camera should point towards you, like in the photo. Once you get the hands closer to the camera, you’ll notice they become visible over keyboard and then the closest fingertip movement is analyzed; if there is down-up movement and what is the key pressed.
The approach could be improved, but that would be out of scope of this tutorial.
Eventually, you’ll manage to type with not that many mistakes. Use the Delete key to fix them; this is the reason why I made it a bit larger and easier to hit. The captured screenshot animation shows how it works.
The approach has two steps; pre-process every pixel on GPU and identify potential candidates and then process them on CPU. The algorithms are expected to be highly tailored for the use cases. The algorithm split could be explained like this:
GPU:
CPU:
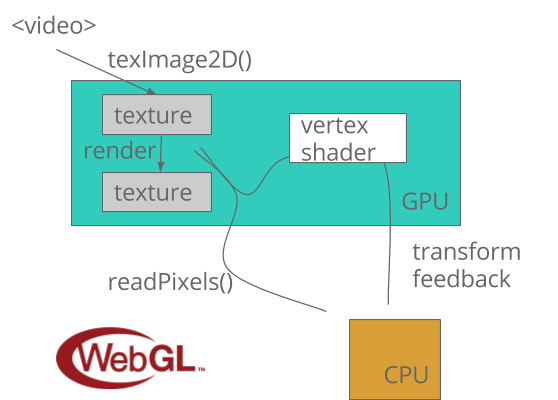
WebGL API used for this is presented on the picture.
The part using video and texImage2D is described in previous tutorial. In short, we follow this steps:
1. Create HTML <video> tag.
2. Call getUserMedia(constraint_to_depth_stream) to get the depth stream. If algorithm requires it, get the color stream, too.
3. Set the stream as video source, e.g. video.srcObject = stream;
4. Upload the latest captured depth video frame to texture, e.g.
gl.texImage2D(gl.TEXTURE_2D, 0, gl.R32F, gl.RED, gl.FLOAT, video);
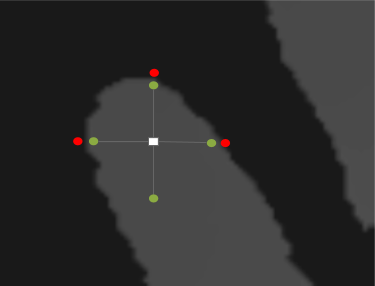
This tutorial is describing transform feedback path. In the example we follow here, vertex shader code detects the points that are the centers of the area, as described by the picture:
So, we sample around and increase the distance of samples to the point. The idea is that on distance D (the green dots on the picture), all of the samples are inside the finger area, but on the distance D + 3, three or four out of four samples (the red dots) are outside the area.
The part of vertex shader code doing this is:
// Vertex shader code; transform feedback returns |depth|.
// We have previously checked that the point is at least 3
// pixels away from the edge, so start from i = 4.0.
float i = 4.0;
float number_of_dots_inside = 4.0;
for (; i < MAX_DISTANCE; i += 3.0) {
// Sample the texels like on the picture on the left.
d_0 = texture(s_depth, depth_tex_pos + vec2(i, 0.0) * step).r;
d_90 = texture(s_depth, depth_tex_pos + vec2(0.0, i) * step).r;
d_180 = texture(s_depth, depth_tex_pos - vec2(i, 0.0) * step).r;
d_270 = texture(s_depth, depth_tex_pos - vec2(0.0, i) * step).r;
if (d_0 * d_90 * d_180 * d_270 == 0.0) {
number_of_dots_inside = sign(d_0) + sign(d_90) +
sign(d_180) + sign(d_270);
break;
}
}
// > 7.0 serves to eliminate "thin" areas. We pass depth > 1.0 through
// transform feedback, so that CPU side of algorithm would understands
// that this point is "center of fingertip" point and process it further.
if (number_of_dots_inside <= 1.0 && i > MIN_DISTANCE) {
// Found it! Pack also the distance in the returned value.
depth = i + depth;
}
We start this by getting the transform feedback buffer data. The code includes the calls issuing the Step 1 and getting the buffer data, using getBufferSubData, and looks like:
gl.bindTransformFeedback(gl.TRANSFORM_FEEDBACK, gl.transform_feedback)
gl.bindBufferBase(gl.TRANSFORM_FEEDBACK_BUFFER, 0, gl.tf_bo)
gl.beginTransformFeedback(gl.POINTS);
gl.drawArrays(gl.POINTS, 0, tf_output.length);
gl.endTransformFeedback();
gl.bindBufferBase(gl.TRANSFORM_FEEDBACK_BUFFER, 0, null)
gl.disable(gl.RASTERIZER_DISCARD);
gl.bindBuffer(gl.TRANSFORM_FEEDBACK_BUFFER, gl.tf_bo);
gl.getBufferSubData(gl.TRANSFORM_FEEDBACK_BUFFER, 0, tf_output, 0, tf_output.length);
gl.bindBuffer(gl.TRANSFORM_FEEDBACK_BUFFER, null);
After that, on CPU side, we:
1. attempt to compensate for the noise and identify the fingertip closest to the camera,
2. pass the position of the fingertip to the shader rendering it,
3. find the keyboard key under the fingertip and display it as hovered,
4. detect press-down-and-up gesture of the single fingertip and
5. issue a key click if detecting press-down-and-up gesture.
Let’s start with the data we get from GPU (Step 1). White dots are identified as centers of the area, fingertip candidates. The red dot is the one among them that is the closest to the camera.
In the CPU side step, we take only that one, the red dot, and try to further stabilize it by calculating the center of mass (this would be the yellow dot on the pictures) of the shape around it. This step helps in reducing the noise, that is intrinsic to the infrared based depth sensing camera technology. Roughly speaking, the yellow dot is then the calculated center of mass of all connected points to the red point. When the finger is not moving, the yellow dot is more stable than the red, like on the picture.
The algorithm implementing this is given in extractMinumums() function. Starting from the red dot, we enumerate the surrounding points on the same distance, as if spreading the waves of concentrical circles. For each point of the circle, we access the elements that is towards the center (the red point) to check if the point is connected to the red point. This way, we enumerate all the connected points to the red and calculate the average coordinate (i.e. the center of mass).
The approach could be improved by tracking all of the fingers; not only that it would enable simultaneous key presses, but the click detection would be more robust as we would not only analyze the single closest point to to camera. Instead, it might make more sense to spend some time on different gesture recognition, e.g. low latency hand gesture click made of quick contact of thumb and pointing finger and try to incorporate it in a game. The next tutorial should be about it.